Prospettive di mercato del software di web scraping:
Il mercato dei software di web scraping ha raggiunto i 782,5 milioni di dollari nel 2025 e si prevede che raggiungerà i 2,7 miliardi di dollari entro il 2035, con una crescita di circa il 13,2% CAGR durante il periodo di previsione, ovvero tra il 2026 e il 2035. Nel 2026, il valore del settore dei software di web scraping è stimato in 875,46 milioni di dollari.
Si prevede che l'aumento dell'e-commerce avrà un impatto su questa crescita. A livello globale, si stima che entro il 2023 ci saranno oltre 3 miliardi di acquirenti digitali, pari a circa il 32% della popolazione mondiale. La necessità di software di web scraping aumenterà quindi probabilmente. Si prevede che una tecnica chiamata web scraping verrà utilizzata spesso per raccogliere dati di prodotto da diversi siti di e-commerce, tra cui Google Shopping, Amazon, eBay e altri.
Oltre a ciò, le agenzie immobiliari utilizzano spesso il web scraping per aggiungere immobili in vendita o in affitto ai propri database. Un'agenzia immobiliare, ad esempio, potrebbe utilizzare il web scraping per sviluppare un'API che aggiorna automaticamente il proprio sito web con dati aggiornati. In questo modo, la persona che trova l'annuncio sul proprio sito web diventa l'agente e rappresenta l'immobile.
Chiave Software di web scraping Riepilogo delle Analisi di Mercato:
Punti salienti regionali:
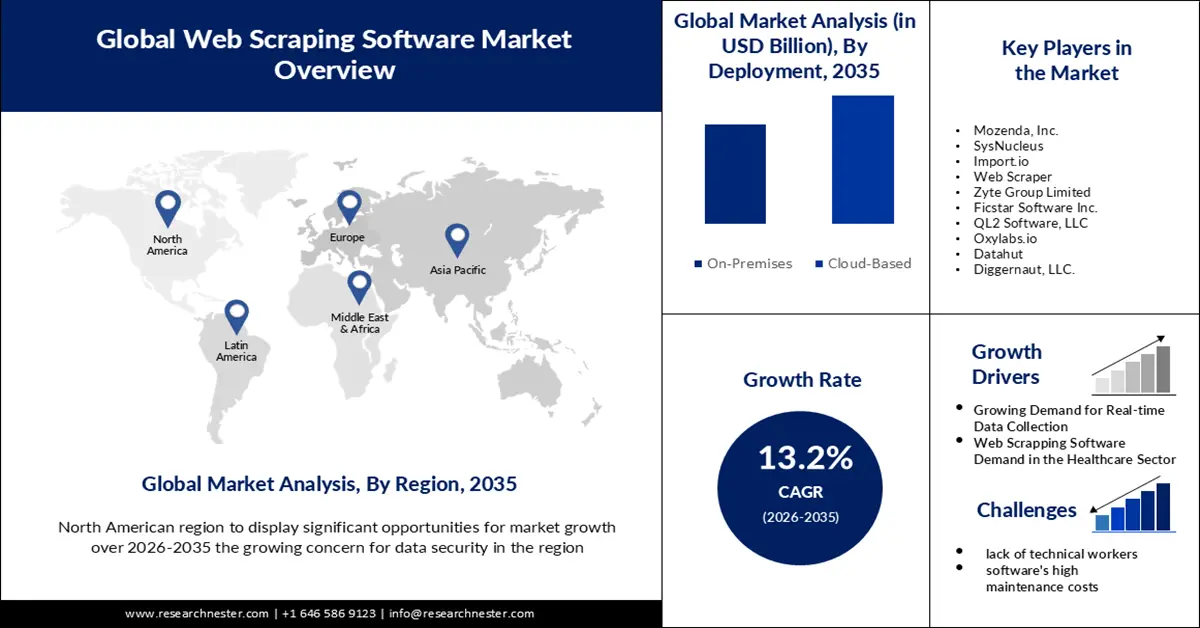
- Si prevede che la regione del Nord America nel mercato dei software di scraping raggiungerà una quota del 45% entro il 2035, attribuibile alla crescente necessità di ottimizzazione delle strategie di prezzo in tutti i settori e alla maggiore enfasi sulla sicurezza dei dati.
- Si prevede che la regione Asia-Pacifico si assicurerà una quota di fatturato significativa entro il 2035, determinata dalla forte presenza delle PMI e dalla limitata propensione a investire in strumenti premium in mezzo a numerose alternative di software libero.
Informazioni sui segmenti:
- Si prevede che il segmento basato su cloud nel mercato dei software di scraping si assicurerà una quota di fatturato notevole entro il 2035, supportato dall'adozione crescente di soluzioni basate su cloud e dal crescente utilizzo di architetture di scraping accessibili da remoto e abilitate tramite API.
- Si prevede che il segmento delle grandi imprese acquisirà una quota di mercato sostanziale entro il 2035, trainato dalla crescente dipendenza delle aziende dalle capacità di analisi e raccolta dati automatizzate su larga scala.
Principali tendenze di crescita:
- Crescente domanda di raccolta dati in tempo reale
- Domanda di software di web scraping nel settore sanitario
Sfide principali:
- Blocchi CAPTCHA e blocchi IP
- La mancanza di personale tecnico potrebbe impedire l'espansione del mercato dei software di web scraping.
Attori principali: Mozenda, Inc., SysNucleus, Import.io, Web Scraper, Zyte Group Limited, Ficstar Software Inc., QL2 Software, LLC, Oxylabs.io, Datahut, Diggernaut, LLC., Apify, Parsehub, X-Byte Enterprise Crawling, Diffbot, Grepsr.
Globale Software di web scraping Mercato Previsioni e prospettive regionali:
Proiezioni di crescita e dimensioni del mercato:
- Dimensioni del mercato nel 2025: 782,5 milioni di USD
- Dimensioni del mercato nel 2026: 875,46 milioni di USD
- Dimensioni previste del mercato: 2,7 miliardi di USD entro il 2035
- Previsioni di crescita: 13,2%
Dinamiche regionali chiave:
- Regione più grande: Europa
- Regione in più rapida crescita: Asia Pacifico
- Paesi dominanti: Stati Uniti, Cina, Germania, India, Giappone
- Paesi emergenti: Cina, India, Brasile, Messico, Turchia
Last updated on : 25 November, 2025
Mercato del software di web scraping: fattori di crescita e sfide
Fattori di crescita
- Domanda crescente di raccolta dati in tempo reale: poiché la maggior parte dei siti web cambia regolarmente, sia in termini di struttura, formato che di contenuti, il web scraping in tempo reale è una funzionalità essenziale per qualsiasi scraper online. Solo un servizio di web scraping in tempo reale può avvisare l'utente di tali cambiamenti non appena si verificano. Esempi concreti di dati costantemente aggiornati includono prezzi delle azioni, annunci immobiliari, previsioni del tempo e variazioni di prezzo.
- Domanda di software di web scraping nel settore sanitario: il contatto interpersonale non è più l'unica fonte di informazioni per il settore sanitario. Inoltre, le aziende sanitarie hanno adottato la digitalizzazione in modo distintivo e, per stare al passo con i tempi, operatori del settore come medici, infermieri, pazienti e farmacisti stanno migliorando le proprie competenze tecniche. Nell'attuale sistema sanitario, in cui le decisioni vengono prese esclusivamente sulla base dei dati, il web scraping può migliorare la vita, istruire le persone e aumentare la consapevolezza. Nel settore sanitario, il web scraping può migliorare la vita offrendo soluzioni sensate, poiché le persone ora dipendono da più di medici e farmacisti. Il settore sanitario avrà accesso a 50 petabyte di dati. Un'ampia gamma di dati, tra cui cartelle cliniche delle assicurazioni sanitarie, esigenze e requisiti legislativi, risultati di ricerche e altro ancora, è ospitata in quest'area. Alcune importanti conclusioni che si possono trarre da questi dati sono le seguenti.
- Utilizzo crescente di tecnologie avanzate per il web crawling: la crescente necessità di dati di qualità superiore sta rendendo il web scraping sempre più importante per le aziende di tutto il mondo. Internet ospita una fonte infinita di dati non strutturati e, con essi, opportunità inesplorate. Selenium può essere utilizzato per imitare il processo di accesso a una pagina web tramite un browser web convenzionale. Quando è necessario estrarre testo pulito e titoli di accompagnamento, Boilerpipe è un'ottima opzione. Un pacchetto Java chiamato Boilerpipe è stato creato appositamente per estrarre dati strutturati e non strutturati dalle pagine web. Ha la capacità di rimuovere elementi HTML non necessari e altri contenuti di sfondo dai siti web in modo intelligente.
Sfide
- Blocchi CAPTCHA e blocchi IP: il processo di scraping dei dati dai siti web non è sempre semplice. Il filtraggio IP e i CAPTCHA sono solo due delle numerose difficoltà che gli utenti possono incontrare durante il recupero dei dati. Queste tecniche vengono impiegate dai proprietari delle piattaforme come misura anti-web scraping, che può impedire l'accesso dei clienti ai dati. Il Fully Automated Public Turing Test to Tell Computers and Humans Apart, o CAPTCHA, viene utilizzato per identificare e impedire ai bot di accedere ai siti web. Limitare le registrazioni ai servizi agli utenti umani e prevenire l'aumento dei ticket sono gli obiettivi principali dei CAPTCHA. Non solo compromettono le tecniche SEO, ma rappresentano anche una minaccia per bot ben funzionanti come Googlebot, che raccoglie contenuti da Internet e li assembla in un indice ricercabile per il motore di ricerca Google. Il blocco degli indirizzi IP è il metodo più utilizzato per impedire ai web scraper di accedere ai dati di un sito web. In genere, ciò accade quando un sito web rileva che numerose richieste provengono dallo stesso indirizzo IP. Se volesse interrompere l'attività di scraping, il sito web potrebbe proibire completamente l'indirizzo IP o limitarne l'accesso.
- La mancanza di personale tecnico potrebbe impedire l'espansione del mercato dei software di web scraping.
- Gli elevati costi di manutenzione del software potrebbero ostacolare l'espansione del mercato.
Dimensioni e previsioni del mercato del software di web scraping:
| Attribut du rapport | Détails |
|---|---|
|
Anno base |
2025 |
|
Anno di previsione |
2026-2035 |
|
CAGR |
13,2% |
|
Dimensione del mercato dell'anno base (2025) |
782,5 milioni di dollari |
|
Dimensione del mercato prevista per l'anno (2035) |
2,7 miliardi di dollari |
|
Ambito regionale |
|
Segmentazione del mercato del software di web scraping:
Analisi del segmento di distribuzione
Si prevede che il segmento basato su cloud nel mercato dei software di web scraping acquisirà una quota di fatturato considerevole entro la fine del 2035. Il mercato delle soluzioni basate su cloud si sta espandendo in modo significativo. I vantaggi degli strumenti di web scraping online basati su cloud stanno guidando la crescita di nuove categorie. Le estensioni del browser, come quelle di Google Chrome, vengono spesso utilizzate per abilitare i servizi di cloud scraping; il vero e proprio processo di scraping avviene sul cloud o sul server. Possono quindi essere configurate e accessibili da qualsiasi luogo o dispositivo (Windows, Mac, Linux, Web, Smartphone). La maggior parte dei servizi di estrazione dati basati su cloud fornisce API che consentono ai programmatori di utilizzare la propria piattaforma per creare codice o script per estrarre dati dai siti web. I programmi di web scraping locali non dispongono di questa funzionalità. Anche questo gioca un ruolo significativo nell'espansione del segmento. Il mercato delle app cloud ha un valore di oltre 150 miliardi di dollari. Entro il 2025, 200 ZB di dati saranno conservati nel cloud. Il cloud archivia il 60% di tutti i dati aziendali a livello mondiale.
Analisi dei segmenti di dimensione dell'organizzazione
Entro la fine del 2035, il segmento delle grandi imprese è destinato a conquistare una quota di mercato sostanziale nel software di web scraping. Il web scraping consente alle aziende di raccogliere e organizzare automaticamente i dati dai siti web, consentendo loro di ottenere enormi quantità di dati da Internet nelle grandi aziende. Le organizzazioni possono creare nuovi set di dati utilizzando questi dati, che possono essere utilizzati in vari modi per l'analisi e l'implementazione. Il web scraping è essenziale per le aziende di tutte le dimensioni, ma è principalmente scelto dalle grandi imprese. Il software di web scraping è uno strumento prezioso sia per il settore della vendita al dettaglio che per quello manifatturiero. Può essere utilizzato per una varietà di attività, come il monitoraggio delle strategie di prezzo della concorrenza, il monitoraggio della conformità dei produttori ai requisiti di prezzo minimo, la raccolta di immagini e descrizioni di prodotti da diversi produttori, il monitoraggio del feedback dei clienti e altro ancora.
La nostra analisi approfondita del mercato globale dei software di web scraping include i seguenti segmenti:
Distribuzione |
|
Dimensione dell'organizzazione |
|
Applicazione |
|
Utente finale |
|

Vishnu Nair
Responsabile dello sviluppo commerciale globalePersonalizza questo rapporto in base alle tue esigenze — contatta il nostro consulente per approfondimenti e opzioni personalizzate.
Mercato del software di web scraping - Analisi regionale
Approfondimenti sul mercato nordamericano
Si stima che il mercato del software di web scraping in Nord America rappresenterà la quota di fatturato maggiore, pari al 45%, entro il 2035. Il software di web scraping è necessario in quest'area per le aziende di diversi settori, come lo sport, il trasporto aereo e i trasporti, al fine di definire strategie di prezzo adeguate. Il software di web scraping è ora più importante che mai nella regione per tenersi al passo con gli sviluppi aziendali, in particolare nel settore dei trasporti, dove le complesse strutture dei biglietti e i prezzi dinamici hanno aumentato la concorrenza sul mercato. Inoltre, le crescenti preoccupazioni relative alla sicurezza dei dati stanno supportando la crescita del mercato in questa regione. Negli Stati Uniti, nel 2022, si sono verificati quasi 1801 casi di compromissione dei dati.
Approfondimenti sul mercato APAC
Si stima che la regione Asia-Pacifico nel mercato dei software di web scraping deterrà una quota di fatturato significativa entro la fine del 2035. A causa della forte rivalità, la maggior parte delle aziende del settore dei software di web scraping fornisce i propri prodotti gratuitamente per un periodo di tempo limitato nella regione Asia-Pacifico. Di conseguenza, molte aziende si rifiutano di investire in attrezzature che potrebbero ridurre i costi operativi. Inoltre, a causa della disponibilità di diversi fornitori di software, le piccole e medie imprese (PMI) dominano il settore dei software di web scraping e sono meno propense a investire in software premium, preferendo utilizzare soluzioni complementari. Si prevede che tutti questi problemi ostacoleranno l'espansione del mercato nella regione.

Attori del mercato del software di web scraping:
- Octopus Data Inc.
- Panoramica aziendale
- Strategia aziendale
- Offerte di prodotti chiave
- Performance finanziaria
- Indicatori chiave di prestazione
- Analisi del rischio
- Sviluppo recente
- Presenza regionale
- Analisi SWOT
- Mozenda, Inc.
- SysNucleus
- Import.io
- Web Scraper
- Zyte Group Limited
- Ficstar Software Inc.
- QL2 Software, LLC
- Oxylabs.io
- Datahut
- Diggernaut, LLC.
- Apify
- Parsehub
- Scansione aziendale X-Byte
- Diffbot
- UiPath Inc.
- Grepsr
Sviluppi recenti
- Il progetto pro bono di Oxylabs , "Project 4β", ha annunciato una nuova partnership con Debunk.org, un'organizzazione la cui missione è contrastare la propaganda sponsorizzata dai governi e la disinformazione su Internet. Attraverso la partnership, Oxylabs fornirà a Debunk.org l'accesso gratuito alla sua tecnologia di web scraping all'avanguardia e alle sue conoscenze per combattere il materiale falso su Internet.
- Uipath ha annunciato il lancio del web scraping con l'ausilio dell'esperienza di automazione dell'interfaccia utente. Utilizzando la nuova tecnologia, è possibile accedere facilmente a dati strutturati, tabelle HTML, HREF o SRC. Consente di ottenere dati ordinati per colonne specifiche. Inoltre, l'utente può raccogliere informazioni da diverse pagine web con questo nuovo web scraping.
- Report ID: 5041
- Published Date: Nov 25, 2025
- Report Format: PDF, PPT
- Esplora un’anteprima delle principali tendenze di mercato e degli approfondimenti
- Rivedi tabelle di dati campione e suddivisioni per segmento
- Vivi la qualità delle nostre rappresentazioni visive dei dati
- Valuta la struttura del nostro rapporto e la metodologia di ricerca
- Dai uno sguardo all’analisi del panorama competitivo
- Comprendi come vengono presentate le previsioni regionali
- Valuta la profondità del profilo aziendale e del benchmarking
- Anteprima di come gli insight attuabili possano supportare la vostra strategia
Esplora dati e analisi reali
Domande frequenti (FAQ)
Software di web scraping Ambito del rapporto di mercato
Il campione gratuito include le dimensioni attuali e storiche del mercato, le tendenze di crescita, grafici e tabelle regionali, profili aziendali, previsioni per segmento e altro ancora.
Contatta il nostro esperto




Copyright © 2026 Research Nester. Tutti i diritti riservati.
