合成數據生成市場展望:
2025 年,合成資料產生市場規模超過 4.4716 億美元,預計到 2035 年將達到 87.9 億美元,在預測期內(即 2026 年至 2035 年)的複合年增長率約為 34.7%。 2026 年,合成資料產生的產業規模估計為 5.8681 億美元。
市場成長主要歸因於自動駕駛汽車感測器校準和開發中合成數據的使用日益增加。此外,汽車工程師利用合成資料建構模擬真實駕駛條件的虛擬環境。據估計,到2035年,自動駕駛汽車預計將創造3,000億至4,300億美元的收入。美國保險監督官協會發布的數據預計,到2030年,美國道路上將有450萬輛自動駕駛汽車。這些因素預計將在預測期內推動合成數據生成市場的發展。
合成資料被用於訓練各領域的人工智慧模型,透過消除偏差和添加新的領域知識來提升模型效能。產生資料的其他日益增長的用途包括在缺乏真實資料的情況下訓練模型。 Research Nester 的數據顯示,目前有 34% 的公司正在使用人工智慧,另有 42% 的公司正在探索該領域。在快速發展的人工智慧領域,合成資料集的利用和創建變得越來越重要。
關鍵 合成數據生成 市場洞察摘要:
區域亮點:
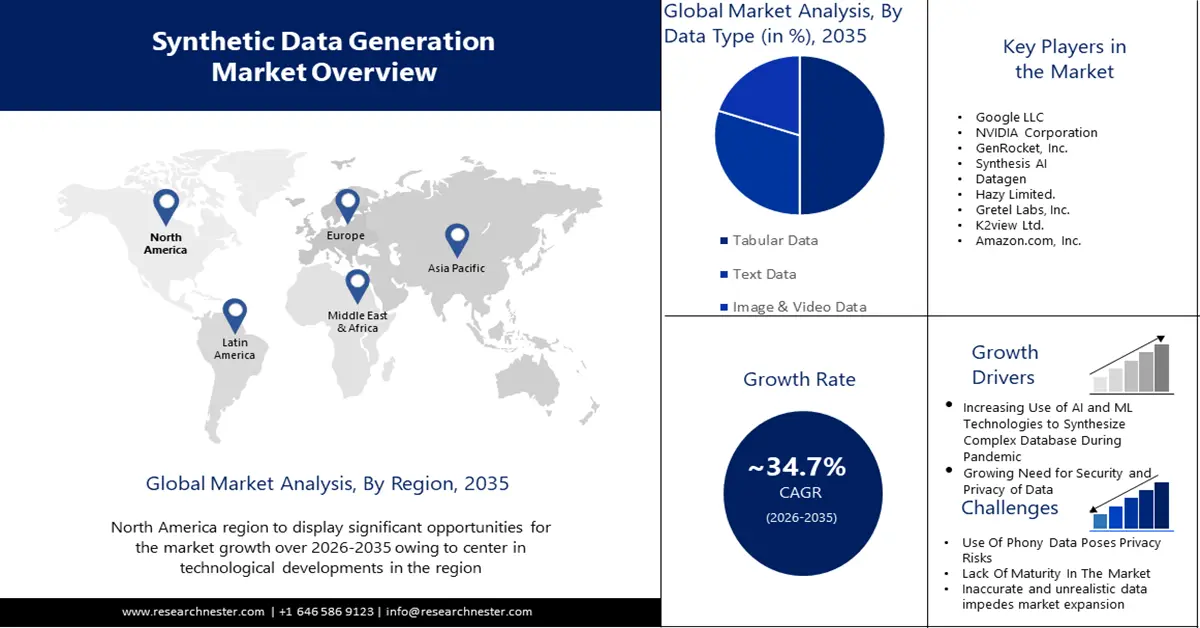
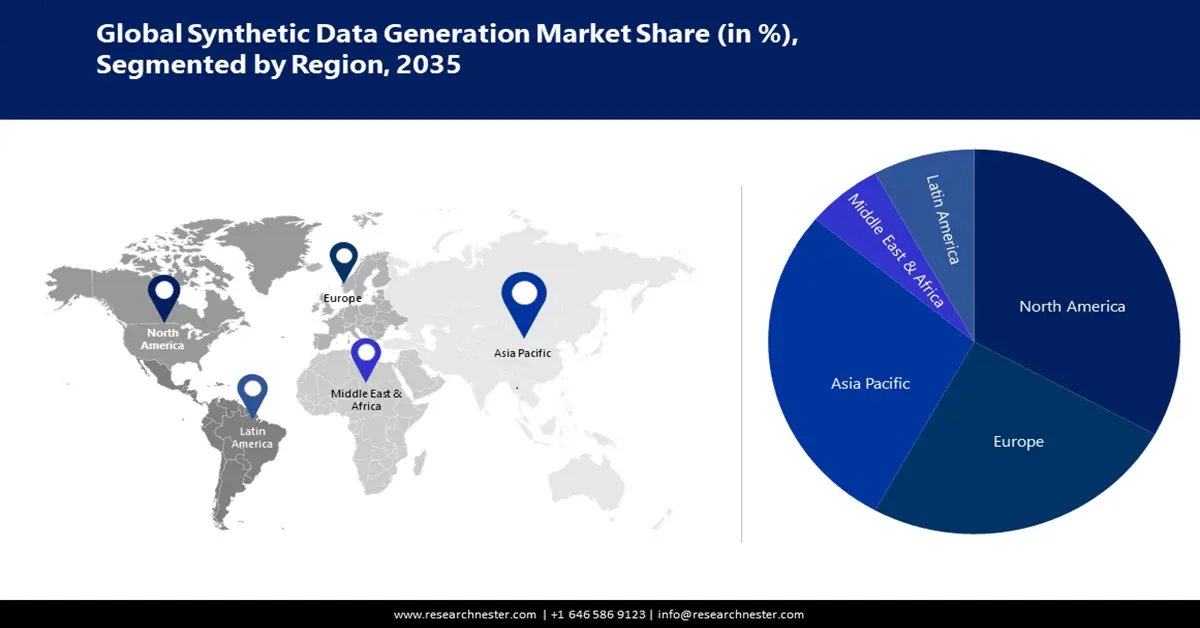
- 預測期內,受研發投入、人工智慧策略和智慧合成數據應用的推動,亞太地區合成數據生成市場將佔據 38% 以上的份額,2026-2035 年。
- 預測期內,受人工智慧/機器學習創新的集中以及對安全合成資料的需求的推動,北美市場將佔據 33% 的份額,2026-2035 年。
細分市場洞察:
- 預計到 2035 年,合成資料產生市場中的表格資料細分市場將佔據 50% 的份額,這得益於隱私問題和資料安全問題導致的合成表格資料需求的增加。
- 預計到 2035 年,合成資料產生市場中的測試資料管理細分市場將佔據 35% 的份額,這得益於對用於測試和驗證的高品質資料的需求不斷增長。
主要成長趨勢:
- 資料安全需求日益增長
- 大型語言模型 (LLM) 的使用日益增加
主要挑戰:
- 不準確且不切實際的數據阻礙了市場擴張
- 相關的倫理考量
主要參與者:Google LLC、NVIDIA Corporation、GenRocket, Inc.、Synthesis AI、Datagen、Hazy Limited.、Gretel Labs, Inc.、K2view Ltd.、Amazon.com, Inc.。
全球 合成數據生成 市場 預測與區域展望:
市場規模與成長預測:
- 2025年市場規模: 4.4716億美元
- 2026年市場規模: 5.8681億美元
- 預計市場規模:到 2035 年將達到 87.9 億美元
- 成長預測:複合年增長率34.7%(2026-2035)
主要區域動態:
- 最大地區:亞太地區(到 2035 年佔 38%)
- 成長最快的地區:亞太地區
- 主要國家:美國、中國、德國、英國、日本
- 新興國家:中國、印度、巴西、墨西哥、新加坡
Last updated on : 16 September, 2025
合成數據生成市場的成長動力與挑戰:
成長動力
資料安全需求日益增長:事實證明,合成資料是一種在不損害隱私的情況下釋放資料潛力的有效工具。醫療、金融、保險等各領域的市場參與者都選擇使用合成數據,以最大限度地發揮數據的效用,同時保護消費者隱私。此外,合成資料在解決詐欺偵測、風險建模等關鍵問題方面發揮重要作用。資料外洩案件的驚人發生率迫使市場參與者採取緩解措施。根據《哈佛商業評論》2024 年 2 月發布的報告,2022 年至 2023 年全球資料外洩案件激增 20%。隨著對資料安全和隱私的需求不斷增長,預計市場將顯著增長。
大型語言模型 (LLM) 的應用日益廣泛:大型語言模型的用例包括內容生成、翻譯和在地化、聊天機器人、個人助理等。根據世界經濟論壇 2023 年 10 月發布的數據,WhatsApp、Instagram 和 Facebook 等社群網站將與母公司 Meta 開發的近 30 個人工智慧聊天機器人進行交互,以徹底改變其社群媒體用戶的體驗。各種終端使用者使用這些語言模型進行程式碼產生、詐欺偵測、圖像標註、文字產生和對話式人工智慧。合成數據使這些聊天機器人更加準確,對消費者而言更加實用。
- 疫情期間運用人工智慧和機器學習技術合成複雜資料庫: COVID-19疫情的爆發反映了患者群體的廣泛特徵,並重現了疫情隨時間推移和疫情密集地區的影響。全球流行病學家的數量激增。例如,美國勞工統計局2023年5月發布的報告指出,目前在職的流行病學家數量為10,230人。他們利用大規模合成數據來推斷疫情的影響。
挑戰
不準確和不切實際的數據阻礙了市場擴張:用戶可以測試和共享使用合成數據生成的數據集的虛擬副本。此外,這種方法很難捕捉專業模型和真實世界照片的精細細節。由於合成資料集依賴真實世界的數據,並且會隨著發明和進步而變化,因此很難長期維護合成資料集。因此,組織應定期驗證合成資料的準確性和可靠性。這降低了合成數據的品質和真實性,嚴重阻礙了合成數據生成市場的成長。
相關倫理考量:合成資料的使用增加了與資料隱私和產生資料同意相關的倫理考量。各種資料使用和保護管理框架可能會限制合成資料的使用,並阻礙其可擴展性和應用。偏見和隱私問題的潛在影響預計將阻礙市場成長。
合成資料生成市場規模與預測:
| 報告屬性 | 詳細資訊 |
|---|---|
|
基準年 |
2025 |
|
預測期 |
2026-2035 |
|
複合年增長率 |
34.7% |
|
基準年市場規模(2025年) |
4.4716億美元 |
|
預測年度市場規模(2035年) |
87.9億美元 |
|
區域範圍 |
|
合成數據生成市場區隔:
資料類型細分分析
根據資料類型,預計在預測期內,合成資料產生市場中的表格資料將佔據最大的收入份額,約 50%。近年來,隱私問題使得企業難以取得真實資料。由於這些困難,人們產生了與真實數據相似的合成數據,並將其以有序的表格形式保存。這增加了對表格數據的需求,預計在預測期內,表格數據的需求將以顯著的複合年增長率增長。企業可以利用生成對抗網路 (GAN) 創建合成表格數據,從而提高營運數據的安全性和隱私性。
應用細分分析
根據應用情況,預測期內,合成資料產生市場中的測試資料管理部分預計將佔據最大份額,約 35%。對用於測試和驗證的高品質數據日益增長的需求將推動市場發展。測試資料管理允許開發人員使用真實資料測試應用程序,而不會危及資料安全。例如,Infosys 測試資料管理套件提供了基於 Web 的工具,用於集中管理測試資料。該套件為數據和測試配置團隊提供了一個簡單易用的一次性介面。該工具包具有測試資料生成、屏蔽和提取功能,以及基於資料請求的工作流程。
我們對全球合成數據生成市場的深入分析包括以下部分:
成分 |
|
部署模式 |
|
造型類型 |
|
奉獻 |
|
資料類型 |
|
垂直的 |
|

Vishnu Nair
全球業務發展主管根據您的需求自訂本報告 — 與我們的顧問聯繫,獲得個人化的洞察與選項。
合成數據生成市場區域分析:
北美市場洞察
北美是技術開發中心,尤其註重數據驅動的突破、人工智慧和機器學習,因此該市場佔據了最大的收入份額,約 33%。由於該地區新創企業、科技公司和研究機構的不斷建立,用於進行實驗和訓練人工智慧模型的高品質合成數據激增。主要市場參與者的存在進一步推動了該地區的市場擴張。美國的組織尋求強有力的解決方案來保護敏感資訊並遏制資料外洩案件。據估計,2024 年該國資料外洩的平均成本為 932 萬美元。此外,研究人員利用合成資料進行藥物試驗,而不會洩漏敏感的患者資訊。
亞太市場洞察
亞太地區的合成數據生成市場預計將佔據第二大收入份額,約佔38%。中國和日本等國家擁有許多注重研發的傑出科技型公司。各國政府正優先投資大數據、人工智慧和機器學習戰略。合成資料正以多種方式被用於提昇道路安全。例如,根據日本國際貿易管理局9月的數據,日本總務省預測,2024年日本的人工智慧系統市場規模將蓬勃發展至近73億美元。大阪大學的研究人員建立了一個超現代框架,可以從城市數位孿生自動產生合成資料集。
合成數據生成市場參與者:
- 微軟公司
- 公司概況
- 商業策略
- 主要產品
- 財務表現
- 關鍵績效指標
- 風險分析
- 近期發展
- 區域影響力
- SWOT分析
- 谷歌有限責任公司
- NVIDIA公司
- GenRocket公司
- 合成人工智慧
- 資料來源
- 朦朧有限公司。
- Gretel Labs公司
- K2view有限公司
- 亞馬遜公司
最新動態
- 2024年3月, Hazy和Unbanx宣布合作開發開放銀行資料所有權平台。這是兩家公司共同努力的結果,旨在為對沖基金、分析師和其他金融機構部署符合道德規範的合成數據合作社,以獲取金融交易數據。
- 2024 年 6 月, NVIDIA Nemotron-4 340B 針對 NVIDIA TensorRT-LLM 和 NVIDIA NeMo 進行了最佳化,可用於醫療保健、製造、零售和金融等多個領域開發商業應用。
- 2024 年 9 月,亞馬遜推出了 Amazon Bedrock,它可用於產生用於合成資料創建的 Python 程式碼。 Amazon Bedrock 工具可協助客戶建立和擴展生成式 AI 應用程式。它是一項用於建立生成式 AI 應用程式的完全託管服務。
- 2024 年 10 月, Gretel與Google Cloud攜手合作,簡化了 BigQuery 中資料分析師的合成資料產生流程。此次整合允許用戶創建其 BigQuery 資料集的隱私保護合成版本。此次合作將賦能客戶保護資料隱私、增強可存取性並加速測試和開發。
- 2024 年 10 月, Teledyne FLIR將 Prism AIMMGen 推向市場,這是一項不受 ITAR 約束的 AI 模型合成資料生成服務,可供系統整合商創建用於急救、商業和國防應用的 AI/ML 產品。
- 2024年10月, Betterdata、MOSTLY AI、DataCebo和Rockfish Data獲得了美國國土安全部 (DHS) 科學技術局 (S&T) 的合同,用於開發能夠生成真實數據模式並降低安全威脅的合成數據功能。這些保護隱私的生成資料平台旨在加速企業級應用程式中 AI 功能的發展。
- Report ID: 5711
- Published Date: Sep 16, 2025
- Report Format: PDF, PPT
- 探索关键市场趋势和洞察的预览
- 查看样本数据表和细分分析
- 体验我们可视化数据呈现的质量
- 评估我们的报告结构和研究方法
- 一窥竞争格局分析
- 了解区域预测的呈现方式
- 评估公司概况与基准分析的深度
- 预览可执行洞察如何支持您的战略
探索真实数据和分析
常见问题 (FAQ)
合成數據生成 市场报告范围




版权所有 © 2026 Research Nester。保留所有权利。
