Perspectivas del mercado de generación de datos sintéticos:
El tamaño del mercado de generación de datos sintéticos superó los USD 447,16 millones en 2025 y se proyecta que alcance los USD 8790 millones para 2035, con una tasa de crecimiento anual compuesta (TCAC) de aproximadamente el 34,7 % durante el período de pronóstico, es decir, entre 2026 y 2035. En 2026, el tamaño de la industria de generación de datos sintéticos se estima en USD 586,81 millones.
El crecimiento del mercado se debe principalmente al creciente uso de datos sintéticos para calibrar y desarrollar sensores en vehículos autónomos. Además, los ingenieros automotrices utilizan datos sintéticos para crear entornos virtuales que simulan las condiciones de conducción reales. Se estima que, para 2035, la conducción autónoma podría generar entre 300 000 y 430 000 millones de dólares en ingresos. Los datos publicados por la Asociación Nacional de Comisionados de Seguros (NSA) prevén que habrá 4,5 millones de vehículos autónomos en las carreteras estadounidenses para 2030. Se prevé que estos factores impulsen el mercado de generación de datos sintéticos durante el período de pronóstico.
Los datos sintéticos se utilizan para entrenar modelos de IA en diversos campos y mejorar su rendimiento eliminando sesgos y aportando nuevos conocimientos del dominio. Otros usos crecientes de los datos generados incluyen el entrenamiento de modelos en ausencia de datos reales. Research Nester sugiere que actualmente el 34 % de las empresas utilizan inteligencia artificial y un 42 % adicional están explorando este campo. En el campo de la inteligencia artificial, en rápida evolución, el uso y la creación de conjuntos de datos sintéticos han adquirido una importancia cada vez mayor.
Clave Generación de datos sintéticos Resumen de Perspectivas del Mercado:
Aspectos regionales destacados:
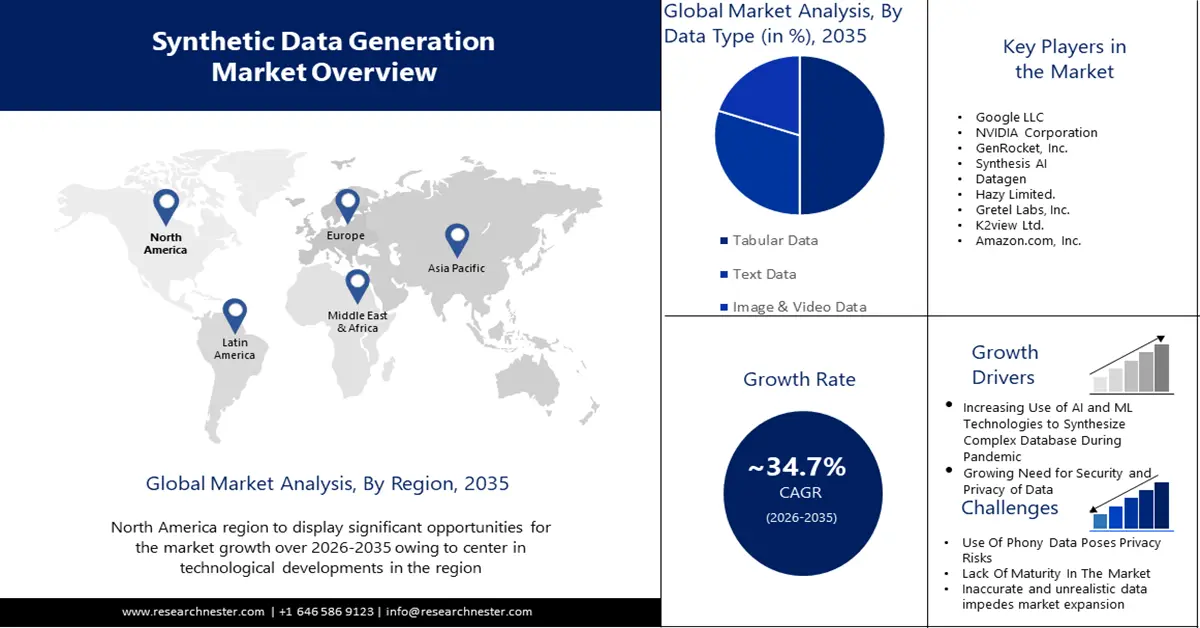
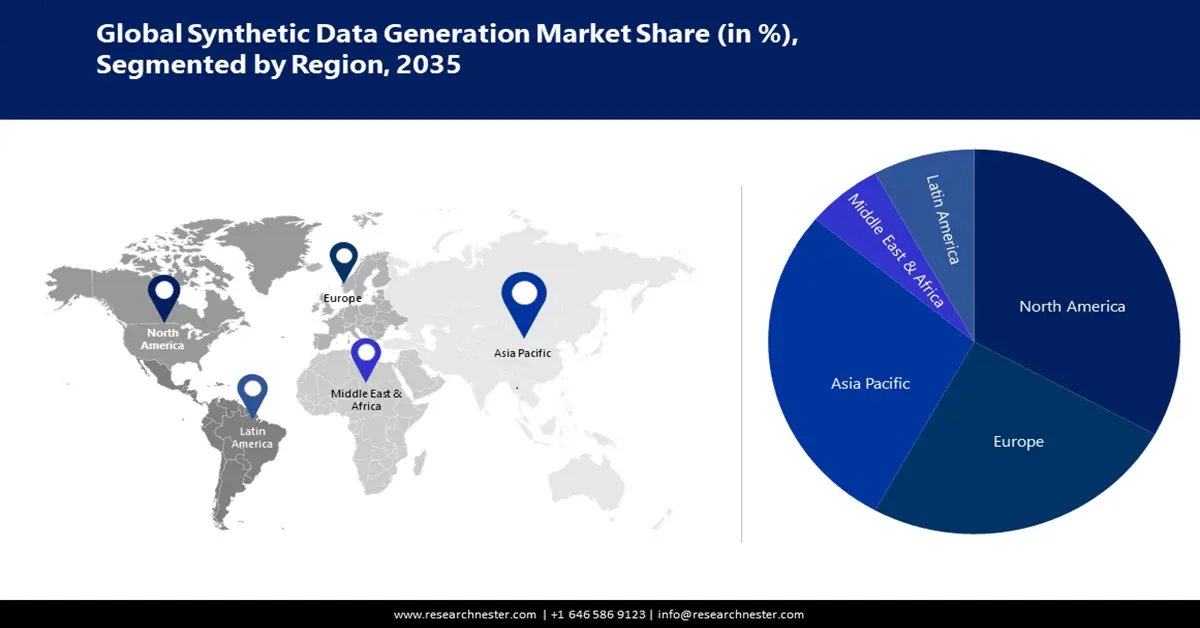
- El mercado de generación de datos sintéticos de Asia Pacífico dominará más del 38% de la participación, impulsado por el aumento de las inversiones en I+D, las estrategias de IA y las aplicaciones inteligentes de datos sintéticos, durante el período de pronóstico 2026-2035.
- El mercado de América del Norte captará una participación del 33%, impulsado por la concentración de la innovación en IA/ML y la demanda de datos sintéticos seguros, durante el período de pronóstico 2026-2035.
Perspectivas del segmento:
- Se espera que el segmento de datos tabulares en el mercado de generación de datos sintéticos alcance una participación del 50 % para 2035, impulsado por la creciente demanda de datos tabulares sintéticos debido a las preocupaciones sobre la privacidad y la seguridad de los datos.
- Se proyecta que el segmento de gestión de datos de prueba en el mercado de generación de datos sintéticos alcance una participación del 35 % para 2035, impulsado por la creciente demanda de datos de alta calidad para pruebas y validación.
Tendencias clave de crecimiento:
- Creciente necesidad de seguridad de datos
- Mayor uso de Modelos de Lenguaje Largos (LLM)
Principales desafíos:
- La aparición de datos inexactos y poco realistas impide la expansión del mercado
- Consideraciones éticas asociadas
Actores clave:Google LLC, NVIDIA Corporation, GenRocket, Inc., Synthesis AI, Datagen, Hazy Limited., Gretel Labs, Inc., K2view Ltd., Amazon.com, Inc.
Global Generación de datos sintéticos Mercado Pronóstico y perspectiva regional:
Proyecciones de tamaño y crecimiento del mercado:
- Tamaño del mercado en 2025: USD 447,16 millones
- Tamaño del mercado en 2026: USD 586,81 millones
- Tamaño proyectado del mercado: USD 8.79 mil millones para 2035
- Previsiones de crecimiento: 34,7 % CAGR (2026-2035)
Dinámicas regionales clave:
- Región más grande: Asia Pacífico (participación del 38 % para 2035)
- Región de más rápido crecimiento: Asia Pacífico
- Países dominantes: Estados Unidos, China, Alemania, Reino Unido, Japón
- Países emergentes: China, India, Brasil, México, Singapur
Last updated on : 16 September, 2025
Impulsores y desafíos del crecimiento del mercado de generación de datos sintéticos:
Factores impulsores del crecimiento
Creciente necesidad de seguridad de datos: Los datos sintéticos han demostrado ser una herramienta eficaz para liberar el potencial de los datos sin comprometer la privacidad. Los actores del mercado en diversos sectores, como la salud, las finanzas y los seguros, están optando por los datos sintéticos para maximizar su utilidad y, al mismo tiempo, proteger la privacidad del consumidor. Además, los datos sintéticos desempeñan un papel fundamental para abordar cuestiones cruciales como la detección de fraudes y la modelización de riesgos. La alarmante tasa de casos de vulneraciones de datos obliga a los actores del mercado a adoptar medidas de mitigación. Según un informe publicado por Harvard Business Review en febrero de 2024, se registró un aumento del 20 % en los casos de vulneración de datos entre 2022 y 2023 a nivel mundial. Debido a la creciente necesidad de seguridad y privacidad de los datos, se prevé que el mercado experimente un crecimiento significativo.
Aumento del uso de Grandes Modelos de Lenguaje (LLM): Los grandes modelos de lenguaje se utilizan en la generación de contenido, la traducción y localización, los chatbots, la asistencia personal, etc. Según datos publicados por el Foro Económico Mundial en octubre de 2023, redes sociales como WhatsApp, Instagram y Facebook interactuarán con casi 30 chatbots de IA de la empresa matriz Meta para revolucionar la experiencia de sus usuarios en redes sociales. Diversos usuarios finales utilizan estos modelos de lenguaje para la generación de código, la detección de fraudes, la anotación de imágenes, la producción de texto y la IA conversacional. Los datos sintéticos hacen que estos chatbots sean precisos y útiles para el consumidor.
- Uso de tecnologías de IA y ML para sintetizar bases de datos complejas durante la pandemia: La llegada de la pandemia de COVID-19 refleja las características de los pacientes a gran escala y recrea el impacto de la pandemia a lo largo del tiempo y en áreas geográficas con alta densidad de pruebas. Se observa un aumento en el número de epidemiólogos en todo el mundo. Por ejemplo, un informe publicado por la Oficina de Estadísticas Laborales de EE. UU. en mayo de 2023 indicó que el número de epidemiólogos empleados era de 10 230. Utilizan datos sintéticos a gran escala para deducir las repercusiones de la pandemia.
Desafíos
La aparición de datos inexactos y poco realistas impide la expansión del mercado: Los usuarios pueden probar y compartir réplicas virtuales de conjuntos de datos creados mediante la producción de datos sintéticos. Además, este método dificulta capturar los detalles finos de modelos especializados y fotografías reales. Mantener el conjunto de datos sintéticos a lo largo del tiempo es difícil, ya que se basa en datos reales y varía debido a las innovaciones y los avances. Por lo tanto, las organizaciones deben verificar periódicamente la precisión y la fiabilidad de los datos sintéticos. Este aspecto obstaculiza considerablemente el crecimiento del mercado de generación de datos sintéticos, al degradar la calidad y el realismo de los mismos.
Consideraciones éticas asociadas: El uso de datos sintéticos aumenta las consideraciones éticas asociadas con la privacidad y el consentimiento de los datos generados. Diversos marcos que regulan el uso y la protección de datos pueden limitar el uso de datos sintéticos y dificultar su escalabilidad y adopción. Se prevé que la posibilidad de sesgo y las preocupaciones sobre la privacidad obstaculicen el crecimiento del mercado.
Tamaño y pronóstico del mercado de generación de datos sintéticos:
| Atributo del informe | Detalles |
|---|---|
|
Año base |
2025 |
|
Período de pronóstico |
2026-2035 |
|
Tasa de crecimiento anual compuesta (TCAC) |
34,7% |
|
Tamaño del mercado del año base (2025) |
USD 447,16 millones |
|
Tamaño del mercado según pronóstico anual (2035) |
USD 8.79 mil millones |
|
Alcance regional |
|
Segmentación del mercado de generación de datos sintéticos:
Análisis de segmentos de tipos de datos
Según el tipo de datos, se prevé que los datos tabulares en el mercado de generación de datos sintéticos representen la mayor participación en los ingresos, con aproximadamente el 50 % durante el período de pronóstico. Recientemente, las preocupaciones sobre la privacidad han dificultado que las empresas obtengan datos reales. Debido a estas dificultades, se generan datos sintéticos que se asemejan a los datos reales y se pueden mantener de forma tabular organizada. Esto aumenta la demanda de datos tabulares, que se prevé que crezca a una tasa de crecimiento anual compuesta (TCAC) notable durante el período proyectado. Las empresas pueden mejorar la seguridad y la privacidad de los datos operativos mediante el uso de redes generativas antagónicas (GAN) para crear datos tabulares sintéticos.
Análisis del segmento de aplicación
Según la aplicación, se espera que el segmento de gestión de datos de prueba en el mercado de generación de datos sintéticos ocupe la mayor cuota, alrededor del 35%, durante el período de pronóstico. La creciente demanda de datos de alta calidad para pruebas y validación impulsará el mercado. La gestión de datos de prueba permite a los desarrolladores probar aplicaciones con datos reales, sin ponerlos en riesgo. Por ejemplo, la suite de gestión de datos de prueba de Infosys ofrece herramientas web para la gestión centralizada de datos de prueba. Esta suite ofrece una interfaz sencilla y de un solo uso para los equipos de aprovisionamiento de datos y pruebas. El kit de herramientas incluye funciones de generación, enmascaramiento y extracción de datos de prueba, junto con un flujo de trabajo basado en solicitudes de datos.
Nuestro análisis en profundidad del mercado global de generación de datos sintéticos incluye los siguientes segmentos:
Componente |
|
Modo de implementación |
|
Tipo de modelado |
|
Ofrenda |
|
Tipo de datos |
|
Vertical |
|

Vishnu Nair
Jefe de Desarrollo Comercial GlobalPersonalice este informe según sus necesidades: conéctese con nuestro consultor para obtener información y opciones personalizadas.
Análisis regional del mercado de generación de datos sintéticos:
Perspectivas del mercado norteamericano
Se atribuye al mercado de generación de datos sintéticos en Norteamérica la mayor participación en ingresos, con un 33% aproximadamente, debido a su importancia como centro de desarrollo tecnológico, con especial énfasis en avances basados en datos, IA y aprendizaje automático. Debido al creciente establecimiento de startups, empresas tecnológicas e instituciones de investigación en esta región, se observa un auge en la demanda de datos sintéticos de alta calidad para realizar experimentos y entrenar modelos de IA. La presencia de importantes actores del mercado impulsa aún más su expansión en la región. Las organizaciones en EE. UU. buscan soluciones robustas para proteger la información sensible y frenar las filtraciones de datos. Se estima que el costo promedio de una filtración de datos en el país será de USD 9,32 millones en 2024. Además, los investigadores utilizan datos sintéticos para ensayos clínicos sin exponer información sensible de los pacientes.
Perspectivas del mercado de Asia Pacífico
Se proyecta que el mercado de generación de datos sintéticos en Asia Pacífico ocupe la segunda mayor cuota de ingresos, con aproximadamente el 38 %. Países como China y Japón albergan destacadas empresas tecnológicas que priorizan la investigación y el desarrollo. Los gobiernos están priorizando la inversión en estrategias de big data, inteligencia artificial y aprendizaje automático. Los datos sintéticos se están aprovechando de diversas maneras para mejorar la seguridad vial. Por ejemplo, según la Administración de Comercio Internacional, en septiembre de 2024 el Ministerio del Interior y Comunicación de Japón predijo que el mercado japonés de sistemas de inteligencia artificial alcanzaría casi los 7300 millones de dólares. Investigadores de la Universidad de Osaka han desarrollado un marco ultramoderno que puede generar automáticamente conjuntos de datos sintéticos a partir de un gemelo digital de una ciudad.
Actores del mercado de generación de datos sintéticos:
- Corporación Microsoft
- Descripción general de la empresa
- Estrategia empresarial
- Ofertas de productos clave
- Desempeño financiero
- Indicadores clave de rendimiento
- Análisis de riesgos
- Desarrollo reciente
- Presencia regional
- Análisis FODA
- Google LLC
- Corporación NVIDIA
- GenRocket, Inc.
- IA de síntesis
- Generación de datos
- Hazy Limitada.
- Laboratorios Gretel, Inc.
- K2view Ltd.
- Amazon.com, Inc.
Desarrollos Recientes
- En marzo de 2024, Hazy y Unbanx anunciaron su colaboración para crear una plataforma de propiedad de datos de banca abierta. Se trata de un esfuerzo conjunto de ambas compañías para implementar cooperativas éticas de datos sintéticos para datos de transacciones financieras dirigidos a fondos de cobertura, analistas y otras instituciones financieras.
- En junio de 2024, NVIDIA Nemotron-4 340B, optimizado para NVIDIA TensorRT-LLM y NVIDIA NeMo para atención médica, fabricación, comercio minorista y finanzas, entre varios otros, para desarrollar aplicaciones comerciales.
- En septiembre de 2024, Amazon lanzó Amazon Bedrock, una herramienta útil para generar código Python para la creación de datos sintéticos. Esta herramienta ayuda a los clientes a crear y escalar aplicaciones de IA generativa. Se trata de un servicio totalmente gestionado para la creación de aplicaciones de IA generativa.
- En octubre de 2024, Gretel y Google Cloud unieron fuerzas para simplificar la generación de datos sintéticos para los analistas de datos en BigQuery. La integración permite a los usuarios crear versiones sintéticas de sus conjuntos de datos de BigQuery que preservan la privacidad. Esta colaboración permite a los clientes proteger la privacidad de los datos, mejorar la accesibilidad y acelerar las pruebas y el desarrollo.
- En octubre de 2024, Teledyne FLIR lanzó al mercado Prism AIMMGen, un servicio de generación de datos sintéticos de modelos de IA libre de ITAR para que los integradores de sistemas creen productos de IA/ML para aplicaciones de primera respuesta, comerciales y de defensa.
- En octubre de 2024, Betterdata, MOSTLY AI, DataCebo y Rockfish Data recibieron contratos de la Dirección de Ciencia y Tecnología (S&T) del Departamento de Seguridad Nacional (DHS) para desarrollar capacidades de datos sintéticos que puedan generar patrones de datos reales y, al mismo tiempo, mitigar las amenazas a la seguridad. Estas plataformas de datos generativos, que preservan la privacidad, están diseñadas para acelerar las capacidades de IA en aplicaciones empresariales.
- Report ID: 5711
- Published Date: Sep 16, 2025
- Report Format: PDF, PPT
- Explore una vista previa de las principales tendencias e ideas del mercado
- Revise tablas de datos de muestra y desgloses por segmento
- Experimente la calidad de nuestras representaciones visuales de datos
- Evalúe nuestra estructura de informe y metodología de investigación
- Obtenga una vista de la análisis del panorama competitivo
- Comprenda cómo se presentan las previsiones regionales
- Evalúe la profundidad del perfilado de empresas y análisis comparativo
- Vea cómo los insights accionables pueden respaldar su estrategia
Explore datos y análisis reales
Preguntas frecuentes (FAQ)
Generación de datos sintéticos Alcance del informe de mercado
La muestra gratuita incluye el tamaño del mercado actual e histórico, tendencias de crecimiento, gráficos y tablas regionales, perfiles de empresas, previsiones por segmento y más.
Conéctate con nuestro experto




Derechos de autor © 2026 Research Nester. Todos los derechos reservados.
