Perspectivas del mercado de software de raspado web:
El tamaño del mercado de software de raspado web superó los USD 782,5 millones en 2025 y se proyecta que alcance los USD 2700 millones para 2035, con un crecimiento anual compuesto (CAGR) de alrededor del 13,2 % durante el período de pronóstico, es decir, entre 2026 y 2035. En 2026, el tamaño de la industria del software de raspado web se estima en USD 875,46 millones.
Se espera que el auge del comercio electrónico influya en este crecimiento. A nivel mundial, se proyecta que habrá más de 3 mil millones de compradores digitales para 2023. Esto representa aproximadamente el 32 % de la población mundial. Por lo tanto, es probable que aumente la necesidad de software de raspado web. Se prevé que una técnica llamada raspado web se utilice con frecuencia para recopilar datos de productos de varios sitios web de comercio electrónico, como Google Shopping, Amazon, eBay y otros.
Además de esto, las inmobiliarias suelen emplear el web scraping para añadir propiedades en venta o alquiler a sus bases de datos. Una agencia inmobiliaria, por ejemplo, podría usar el web scraping de datos MLS para desarrollar una API que actualice automáticamente su sitio web con datos actualizados. De esta forma, quien encuentra este anuncio en su sitio web se convierte en el agente y representa la propiedad.
Clave Software de raspado web Resumen de Perspectivas del Mercado:
Aspectos destacados regionales:
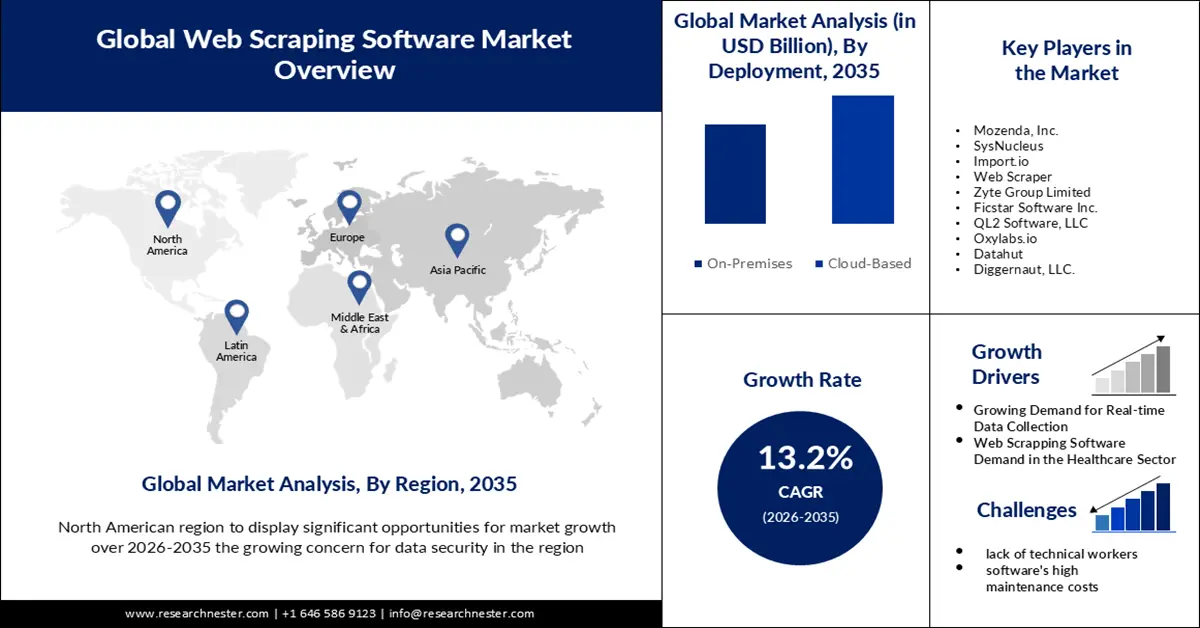
- Se proyecta que la región de América del Norte en el mercado de software de raspado tendrá una participación del 45% para 2035, lo que se atribuye a su creciente necesidad de optimizar la estrategia de precios en todas las industrias y un mayor énfasis en la seguridad de los datos.
- Se prevé que la región Asia Pacífico obtendrá una participación significativa en los ingresos para 2035, determinada por la fuerte presencia de las PYME y la limitada voluntad de invertir en herramientas premium en medio de abundantes alternativas de software gratuito.
Información sobre segmentos:
- Se proyecta que el segmento basado en la nube en el mercado de software de raspado garantizará una participación notable en los ingresos para 2035, respaldado por la creciente adopción de soluciones basadas en la nube y el uso creciente de arquitecturas de raspado accesibles de forma remota y habilitadas para API.
- Se prevé que el segmento de grandes empresas capture una participación de mercado sustancial para 2035, impulsado por la creciente dependencia de las empresas de capacidades automatizadas de recopilación y análisis de datos a gran escala.
Tendencias clave de crecimiento:
- Creciente demanda de recopilación de datos en tiempo real
- Demanda de software de scrapping web en el sector sanitario
Principales desafíos:
- Bloqueadores de CAPTCHA y bloqueadores de IP
- La falta de trabajadores técnicos podría impedir que el mercado de software de raspado web se expanda.
Jugadores clave: Mozenda, Inc., SysNucleus, Import.io, Web Scraper, Zyte Group Limited, Ficstar Software Inc., QL2 Software, LLC, Oxylabs.io, Datahut, Diggernaut, LLC., Apify, Parsehub, X-Byte Enterprise Crawling, Diffbot, Grepsr.
Global Software de raspado web Mercado Pronóstico y perspectiva regional:
Proyecciones de tamaño y crecimiento del mercado:
- Tamaño del mercado en 2025: USD 782,5 millones
- Tamaño del mercado en 2026: USD 875,46 millones
- Tamaño proyectado del mercado: USD 2.700 millones para 2035
- Previsiones de crecimiento: 13,2%
Dinámicas regionales clave:
- Región más grande: Europa
- Región de más rápido crecimiento: Asia Pacífico
- Países dominantes: Estados Unidos, China, Alemania, India, Japón
- Países emergentes: China, India, Brasil, México, Turquía
Last updated on : 25 November, 2025
Mercado de software de raspado web: factores de crecimiento y desafíos
Factores impulsores del crecimiento
- Creciente demanda de recopilación de datos en tiempo real: Dado que la mayoría de los sitios web cambian constantemente, ya sea en cuanto a su estructura, formato o incluso contenido, el web scraping en tiempo real es una función esencial para cualquier scraper en línea. Solo un servicio de web scraping en tiempo real puede notificar al usuario sobre dichos cambios tan pronto como ocurren. Ejemplos reales de datos continuamente actualizados incluyen precios de acciones, listados de bienes raíces, informes meteorológicos y variaciones de precios.
- Demanda de software de extracción de datos web en el sector sanitario: El contacto interpersonal ya no es la única fuente de información para este sector. Además, las empresas sanitarias han adoptado la digitalización de forma innovadora y, para adaptarse a los nuevos tiempos, profesionales como médicos, enfermeros, pacientes y farmacéuticos están mejorando sus habilidades técnicas. En el sistema sanitario actual, donde las decisiones se toman únicamente con base en datos, la extracción de datos web puede mejorar vidas, educar a las personas y aumentar la concienciación. En el sector sanitario, la extracción de datos web puede mejorar vidas al ofrecer soluciones prácticas, ya que las personas ahora dependen de algo más que médicos y farmacéuticos. El sector sanitario tendrá acceso a 50 petabytes de datos. Esta área alberga una amplia gama de datos, incluyendo historiales de seguros médicos, necesidades y requisitos legislativos, resultados de investigaciones, etc. Algunas conclusiones importantes que se pueden extraer de estos datos son las siguientes.
- Uso creciente de tecnología avanzada para el rastreo web: la creciente necesidad de datos de alta calidad hace que el web scraping sea cada vez más importante para empresas de todo el mundo. Internet alberga una cantidad inagotable de datos no estructurados y, con ellos, oportunidades sin explotar. Selenium permite imitar el proceso de acceso a una página web mediante un navegador convencional. Cuando se necesita extraer texto limpio y los títulos que lo acompañan, Boilerpipe es una excelente opción. Un paquete de Java llamado Boilerpipe se creó específicamente para extraer datos estructurados y no estructurados de páginas web. Tiene la capacidad de eliminar elementos HTML innecesarios y otro contenido de fondo de los sitios web de forma inteligente.
Desafíos
- Bloqueadores de CAPTCHA y bloqueadores de IP: El proceso de extraer datos de sitios web no siempre es sencillo. El filtrado de IP y los CAPTCHA son solo dos de las muchas dificultades que los usuarios pueden encontrar al recuperar datos. Los propietarios de plataformas emplean estas técnicas como medida contra el raspado web, lo que puede impedir el acceso de los clientes a los datos. La prueba de Turing pública y totalmente automatizada para distinguir computadoras de humanos, o CAPTCHA, se utiliza para identificar y evitar que los bots accedan a sitios web. Restringir los registros de servicios a usuarios humanos y evitar la inflación de tickets son los principales objetivos de los CAPTCHA. No solo socavan las técnicas de SEO, sino que también representan una amenaza para bots que funcionan correctamente como Googlebot, que recopila contenido de internet y lo ensambla en un índice de búsqueda para el motor de búsqueda de Google. Prohibir direcciones IP es el método más utilizado para evitar que los raspadores web accedan a los datos de un sitio web. Esto suele ocurrir cuando un sitio web detecta que varias solicitudes provienen de la misma dirección IP. El sitio web prohibiría totalmente la dirección IP o restringiría su acceso si desea cesar la actividad de raspado.
- La falta de trabajadores técnicos podría impedir que el mercado de software de raspado web se expanda.
- Los elevados costes de mantenimiento del software podrían impedir la expansión del mercado.
Tamaño y pronóstico del mercado de software de raspado web:
| Atributo del informe | Detalles |
|---|---|
|
Año base |
2025 |
|
Año de pronóstico |
2026-2035 |
|
Tasa de crecimiento anual compuesta (TCAC) |
13,2% |
|
Tamaño del mercado del año base (2025) |
USD 782,5 millones |
|
Tamaño del mercado según pronóstico anual (2035) |
2.700 millones de dólares |
|
Alcance regional |
|
Segmentación del mercado de software de raspado web:
Análisis del segmento de implementación
Se espera que el segmento basado en la nube del mercado de software de raspado web alcance una cuota de mercado considerable para finales de 2035. El mercado de soluciones basadas en la nube está en expansión significativa. Las ventajas de las herramientas de raspado en línea basadas en la nube impulsan el crecimiento de nuevas categorías. Las extensiones de navegador, como las de Google Chrome, se utilizan con frecuencia para habilitar servicios de raspado en la nube; el proceso real de raspado ocurre en la nube o en el servidor. Por lo tanto, se pueden configurar y acceder desde cualquier lugar o dispositivo (Windows, Mac, Linux, web, smartphone). La mayoría de los servicios de extracción de datos basados en la nube ofrecen API para que los programadores puedan usar su plataforma para crear código o scripts y extraer datos de sitios web. Los programas locales de raspado web carecen de esta función. Esto también contribuye significativamente a la expansión del segmento. El mercado de aplicaciones en la nube está valorado en más de 150 000 millones de dólares. Para 2025, 200 ZB de datos se almacenarán en la nube. La nube almacena el 60 % de todos los datos corporativos a nivel mundial.
Análisis de segmentos de tamaño de la organización
Para finales de 2035, el segmento de las grandes empresas está en condiciones de captar una cuota de mercado sustancial del software de raspado web. Este software permite a las empresas recopilar y organizar automáticamente datos de sitios web, lo que les permite obtener enormes cantidades de datos de internet en grandes empresas. Las organizaciones pueden crear nuevos conjuntos de datos a partir de estos datos, que pueden utilizarse de diversas maneras para su análisis e implementación. El raspado web es esencial para empresas de todos los tamaños, pero es una opción predominante entre las grandes empresas. El software de raspado web es una herramienta valiosa tanto para el sector minorista como para el manufacturero. Puede utilizarse para diversas tareas, como el seguimiento de las estrategias de precios de la competencia, el control del cumplimiento de los fabricantes con los requisitos de precio mínimo, la recopilación de imágenes y descripciones de productos de diferentes fabricantes, el seguimiento de las opiniones de los clientes, etc.
Nuestro análisis en profundidad del mercado global de software de raspado web incluye los siguientes segmentos:
Despliegue |
|
Tamaño de la organización |
|
Solicitud |
|
Usuario final |
|

Vishnu Nair
Jefe de Desarrollo Comercial GlobalPersonalice este informe según sus necesidades: conéctese con nuestro consultor para obtener información y opciones personalizadas.
Análisis regional del mercado de software de raspado web
Perspectivas del mercado norteamericano
Se estima que el mercado de software de raspado web en Norteamérica representará la mayor participación en los ingresos, con un 45%, para 2035. Empresas de diversos sectores, como el deportivo, el aéreo y el transporte, necesitan este software en la región para establecer estrategias de precios adecuadas. Este software es ahora más importante que nunca para mantenerse al día con los desarrollos comerciales, especialmente en el sector del transporte, donde la complejidad de las estructuras de billetes y los precios dinámicos han incrementado la competencia en el mercado. Además, la creciente preocupación por la seguridad de los datos impulsa el crecimiento del mercado en esta región. En EE. UU., en 2022, se registraron casi 1801 casos de vulneración de datos.
Perspectivas del mercado de Asia-Pacífico
Se estima que la región Asia Pacífico, dentro del mercado de software de raspado web, tendrá una participación significativa en los ingresos para finales de 2035. Debido a la feroz competencia, la mayoría de las empresas del sector ofrecen sus productos de forma gratuita por tiempo limitado en la región Asia Pacífico. Como resultado, muchas empresas se niegan a invertir en equipos que podrían reducir los costos operativos. Además, debido a la disponibilidad de diversos proveedores de software, las pequeñas y medianas empresas (pymes) dominan la industria del software de raspado web y son menos propensas a invertir en software premium, prefiriendo emplear soluciones complementarias. Se espera que todos estos problemas obstaculicen la expansión del mercado en la región.

Actores del mercado de software de raspado web:
- Datos de pulpo Inc.
- Descripción general de la empresa
- Estrategia empresarial
- Ofertas de productos clave
- Desempeño financiero
- Indicadores clave de rendimiento
- Análisis de riesgos
- Desarrollo reciente
- Presencia regional
- Análisis FODA
- Mozenda, Inc.
- Núcleo del sistema
- Importación.io
- Raspador web
- Grupo Zyte Limitada
- Ficstar Software Inc.
- Software QL2, LLC
- Oxylabs.io
- Cabaña de datos
- Diggernaut, LLC.
- Apificar
- Parsehub
- Rastreo empresarial de X-Byte
- Diffbot
- UiPath Inc.
- Grepsr
Desarrollos Recientes
- El proyecto pro bono de Oxylabs , "Proyecto 4β", ha anunciado una nueva colaboración con Debunk.org, organización cuya misión es contrarrestar la propaganda gubernamental y la desinformación en internet. Gracias a esta colaboración, Oxylabs proporcionará a Debunk.org acceso gratuito a su tecnología de raspado web de vanguardia y a sus conocimientos para combatir el material falso en internet.
- Uipath anunció el lanzamiento del web scraping con la ayuda de la experiencia de automatización de la interfaz de usuario. Gracias a esta nueva tecnología, se puede acceder fácilmente a datos estructurados, tablas HTML, HREF o SRC. Permite obtener datos ordenados por columnas específicas. Además, el usuario puede recopilar información de diferentes páginas web con este nuevo web scraping.
- Report ID: 5041
- Published Date: Nov 25, 2025
- Report Format: PDF, PPT
- Explore una vista previa de las principales tendencias e ideas del mercado
- Revise tablas de datos de muestra y desgloses por segmento
- Experimente la calidad de nuestras representaciones visuales de datos
- Evalúe nuestra estructura de informe y metodología de investigación
- Obtenga una vista de la análisis del panorama competitivo
- Comprenda cómo se presentan las previsiones regionales
- Evalúe la profundidad del perfilado de empresas y análisis comparativo
- Vea cómo los insights accionables pueden respaldar su estrategia
Explore datos y análisis reales
Preguntas frecuentes (FAQ)
Software de raspado web Alcance del informe de mercado
La muestra gratuita incluye el tamaño del mercado actual e histórico, tendencias de crecimiento, gráficos y tablas regionales, perfiles de empresas, previsiones por segmento y más.
Conéctate con nuestro experto




Derechos de autor © 2026 Research Nester. Todos los derechos reservados.
