Перспективы рынка генерации синтетических данных:
Объём рынка генерации синтетических данных в 2025 году превысил 447,16 млн долларов США и, по прогнозам, достигнет 8,79 млрд долларов США к 2035 году, что соответствует среднегодовому темпу роста около 34,7% в прогнозируемый период, то есть с 2026 по 2035 год. В 2026 году объём рынка генерации синтетических данных оценивается в 586,81 млн долларов США.
Рост рынка в первую очередь обусловлен растущим использованием синтетических данных для калибровки и разработки датчиков, используемых в автономных автомобилях. Кроме того, автомобильные инженеры используют синтетические данные для создания виртуальных сред, имитирующих реальные условия вождения. По оценкам, к 2035 году автономное вождение может принести доход в размере от 300 до 430 миллиардов долларов США. Согласно данным, опубликованным Национальной ассоциацией страховых комиссаров, к 2030 году на дорогах США будет 4,5 миллиона беспилотных автомобилей. Прогнозируется, что эти факторы будут стимулировать рынок генерации синтетических данных в прогнозируемый период.
Синтетические данные используются для обучения моделей искусственного интеллекта в различных областях, что позволяет повысить их эффективность за счёт устранения смещений и добавления новых знаний о предметной области. Среди других растущих областей применения сгенерированных данных — обучение моделей без реальных данных. По данным Research Nester, в настоящее время 34% компаний используют искусственный интеллект, а ещё 42% изучают эту область. В быстро развивающейся области искусственного интеллекта использование и создание наборов синтетических данных приобретают всё большую значимость.
Ключ Генерация синтетических данных Сводка рыночной аналитики:
Региональные особенности:
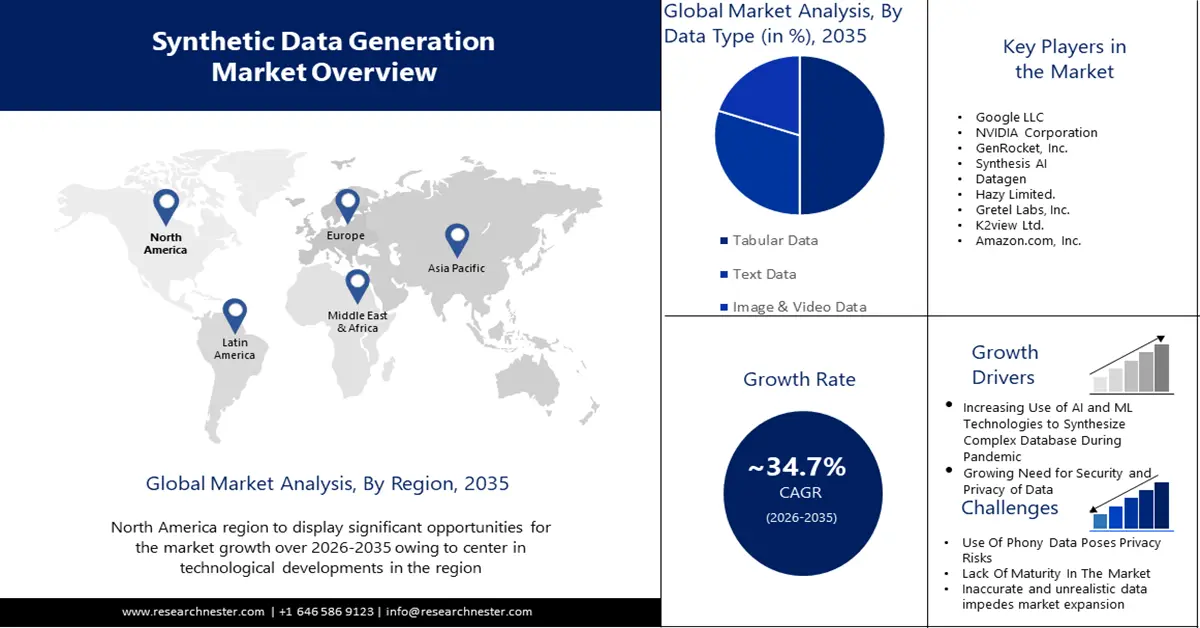
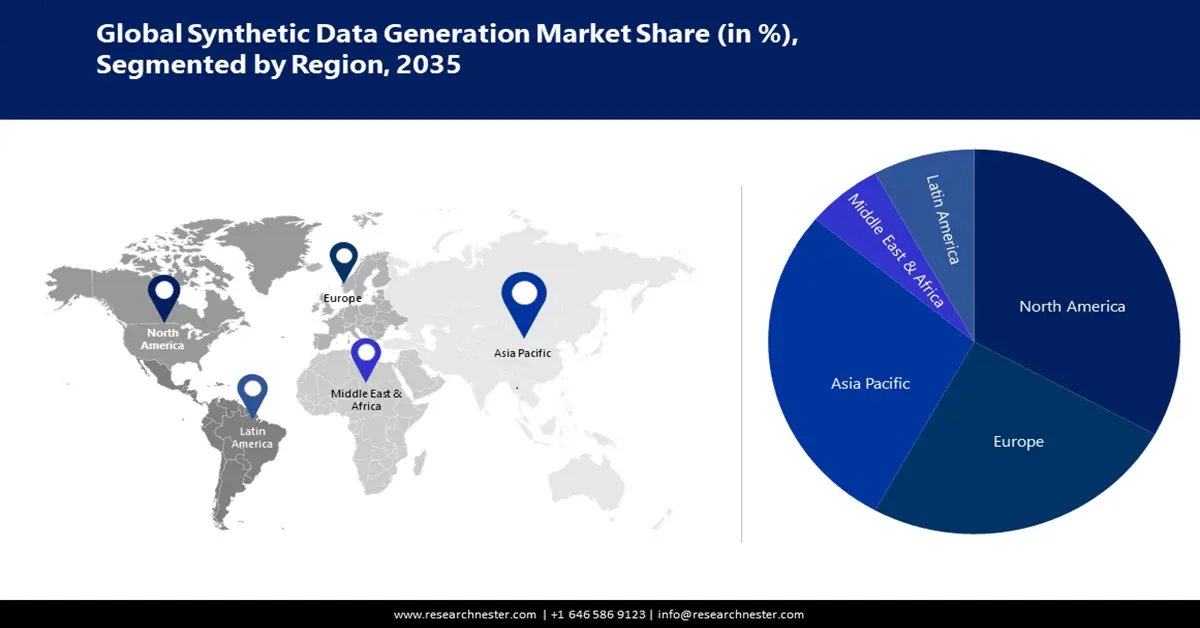
- Азиатско-Тихоокеанский регион займет более 38% рынка генерации синтетических данных благодаря росту инвестиций в НИОКР, стратегиям ИИ и интеллектуальным приложениям для обработки синтетических данных в прогнозируемый период 2026–2035 гг.
- Рынок Северной Америки займет 33% рынка благодаря концентрации инноваций в области ИИ/МО и спросу на безопасные синтетические данные в прогнозируемый период 2026–2035 гг.
Анализ сегмента:
- Ожидается, что к 2035 году доля сегмента табличных данных на рынке генерации синтетических данных достигнет 50%, что обусловлено возросшей потребностью в синтетических табличных данных из-за проблем с конфиденциальностью и безопасностью данных.
- Прогнозируется, что доля сегмента управления тестовыми данными на рынке генерации синтетических данных к 2035 году составит 35%, что обусловлено растущим спросом на высококачественные данные для тестирования и валидации.
Основные тенденции роста:
- Растущая потребность в безопасности данных
- Расширение использования больших языковых моделей (LLM)
Основные проблемы:
- Наличие неточных и нереалистичных данных препятствует расширению рынка
- Сопутствующие этические вопросы
Ключевые игроки:Google LLC, NVIDIA Corporation, GenRocket, Inc., Synthesis AI, Datagen, Hazy Limited., Gretel Labs, Inc., K2view Ltd., Amazon.com, Inc.
Глобальный Генерация синтетических данных Рынок Прогноз и региональный обзор:
Прогнозы размера рынка и роста:
- Объем рынка в 2025 году: 447,16 млн долларов США
- Объем рынка в 2026 году: 586,81 млн долларов США
- Прогнозируемый размер рынка: 8,79 млрд долларов США к 2035 году
- Прогнозы роста: CAGR 34,7% (2026–2035 гг.)
Ключевая региональная динамика:
- Крупнейший регион: Азиатско-Тихоокеанский регион (доля 38 % к 2035 году).
- Самый быстрорастущий регион: Азиатско-Тихоокеанский регион.
- Доминирующие страны: США, Китай, Германия, Великобритания, Япония.
- Развивающиеся страны: Китай, Индия, Бразилия, Мексика, Сингапур.
Last updated on : 16 September, 2025
Факторы роста и проблемы рынка генерации синтетических данных:
Драйверы роста
Растущая потребность в безопасности данных: Синтетические данные доказали свою эффективность в раскрытии потенциала данных без ущерба для конфиденциальности. Участники рынка в различных секторах, таких как здравоохранение, финансы, страхование и т. д., выбирают синтетические данные, чтобы максимизировать полезность данных, а также защитить конфиденциальность потребителей. Кроме того, синтетические данные играют важную роль в решении таких важных задач, как обнаружение мошенничества, моделирование рисков и т. д. Тревожный уровень случаев утечек данных вынуждает участников рынка внедрять методы смягчения последствий. Согласно отчету, опубликованному Harvard Business Review в феврале 2024 года, в период с 2022 по 2023 год во всем мире наблюдался всплеск случаев утечек данных на 20%. Растущая потребность в безопасности и конфиденциальности данных, по прогнозам, рынок станет свидетелем значительного роста.
Расширение использования больших языковых моделей (LLM): большие языковые модели используются в таких областях, как генерация контента, перевод и локализация, чат-боты, персональные помощники и т. д. Согласно данным, опубликованным Всемирным экономическим форумом в октябре 2023 года, такие социальные сети, как WhatsApp, Instagram и Facebook, будут взаимодействовать почти с 30 чат-ботами на основе искусственного интеллекта (ИИ) материнской компании Meta, чтобы кардинально изменить пользовательский опыт своих пользователей. Различные пользователи используют эти языковые модели для генерации кода, обнаружения мошенничества, аннотирования изображений, создания текстов и диалогового ИИ. Синтетические данные делают эти чат-боты точными и полезными для потребителя.
- Использование технологий искусственного интеллекта и машинного обучения для синтеза сложных баз данных во время пандемии: возникновение пандемии COVID-19 отражает характеристики пациентов в широком масштабе и воссоздает последствия пандемии с течением времени и в географических регионах с высокой интенсивностью тестирования. Во всем мире наблюдается резкий рост числа эпидемиологов. Например, в отчете Бюро статистики труда США, опубликованном в мае 2023 года, указано, что число работающих эпидемиологов составляет 10 230 человек. Они используют синтетические данные в больших масштабах для оценки последствий пандемии.
Проблемы
Появление неточных и нереалистичных данных препятствует расширению рынка: пользователи могут тестировать и обмениваться виртуальными копиями наборов данных, созданных с помощью синтетических данных. Более того, этот метод затрудняет сохранение мелких деталей специализированных моделей и фотографий реального мира. Поддержание синтетических данных в актуальном состоянии затруднено, поскольку они основаны на реальных данных и меняются в результате инноваций и усовершенствований. Поэтому организациям следует регулярно проверять точность и надёжность синтетических данных. Этот аспект существенно сдерживает рост рынка генерации синтетических данных, снижая их качество и реалистичность.
Сопутствующие этические соображения: Использование синтетических данных повышает этические требования, связанные с конфиденциальностью данных и согласием на их использование. Различные системы управления использованием и защитой данных могут накладывать ограничения на использование синтетических данных и препятствовать масштабируемости и внедрению. Прогнозируется, что потенциальная предвзятость и проблемы с конфиденциальностью будут препятствовать росту рынка.
Размер и прогноз рынка генерации синтетических данных:
| Атрибут отчёта | Детали |
|---|---|
|
Базовый год |
2025 |
|
Прогнозируемый период |
2026-2035 |
|
CAGR |
34,7% |
|
Размер рынка базового года (2025) |
447,16 млн долларов США |
|
Прогнозируемый размер рынка на год (2035) |
8,79 млрд долларов США |
|
Региональный охват |
|
Сегментация рынка генерации синтетических данных:
Анализ сегментов типов данных
Ожидается, что табличные данные, исходя из типа данных, составят наибольшую долю выручки на рынке генерации синтетических данных – около 50% в прогнозируемый период. В последнее время проблемы конфиденциальности затрудняют для компаний получение реальных данных. Из-за этих трудностей создаются синтетические данные, которые напоминают реальные и могут храниться в организованном табличном виде. Это увеличивает потребность в табличных данных, которая, как ожидается, будет расти значительными среднегодовыми темпами в течение прогнозируемого периода. Компании могут повысить безопасность и конфиденциальность операционных данных, используя генеративно-состязательные сети (GAN) для создания синтетических табличных данных.
Анализ сегмента приложения
Ожидается, что сегмент управления тестовыми данными на рынке генерации синтетических данных, исходя из сферы применения, займет наибольшую долю – около 35% – в прогнозируемый период. Рост спроса на высококачественные данные для тестирования и валидации будет стимулировать развитие рынка. Управление тестовыми данными позволяет разработчикам тестировать приложения с использованием реальных данных, не подвергая данные риску. Например, пакет управления тестовыми данными Infosys предоставляет веб-инструменты для централизованного управления тестовыми данными. Этот пакет предоставляет простой и удобный интерфейс для групп по подготовке данных и тестированию. Набор инструментов включает в себя функции генерации, маскирования и извлечения тестовых данных, а также рабочий процесс на основе запросов данных.
Наш углубленный анализ мирового рынка генерации синтетических данных включает следующие сегменты:
Компонент |
|
Режим развертывания |
|
Тип моделирования |
|
Предложение |
|
Тип данных |
|
Вертикальный |
|

Vishnu Nair
Руководитель глобального бизнес-развитияНастройте этот отчет в соответствии с вашими требованиями — свяжитесь с нашим консультантом для получения персонализированных рекомендаций и вариантов.
Региональный анализ рынка генерации синтетических данных:
Обзор рынка Северной Америки
Рынок генерации синтетических данных в Северной Америке занимает наибольшую долю выручки — около 33%, поскольку это центр технического развития, с особым акцентом на прорывы, основанные на данных, ИИ и машинном обучении. В связи с ростом числа стартапов, технологических компаний и научно-исследовательских институтов в этом регионе наблюдается всплеск высококачественных синтетических данных для проведения экспериментов и обучения моделей ИИ. Присутствие основных игроков на рынке еще больше стимулирует расширение рынка в регионе. Организации в США ищут надежные решения для защиты конфиденциальной информации и предотвращения случаев утечки данных. Было подсчитано, что средняя стоимость утечки данных в стране составляет 9,32 миллиона долларов США в 2024 году. Кроме того, синтетические данные используются исследователями для испытаний лекарственных препаратов без раскрытия конфиденциальной информации пациентов.
Обзор рынка Азиатско-Тихоокеанского региона
Прогнозируется, что рынок генерации синтетических данных в Азиатско-Тихоокеанском регионе займет вторую по величине долю выручки – около 38%. В таких странах, как Китай и Япония, работают крупные технологические компании, уделяющие большое внимание исследованиям и разработкам. Правительства уделяют первоочередное внимание инвестициям в стратегии в области больших данных, искусственного интеллекта и машинного обучения. Синтетические данные используются различными способами для повышения безопасности дорожного движения. Например, по данным Управления международной торговли, в сентябре 2024 года Министерство внутренних дел и коммуникаций Японии прогнозирует, что рынок систем искусственного интеллекта в Японии достигнет почти 7,3 млрд долларов США. Исследователи из Университета Осаки разработали ультрасовременную платформу, которая может автоматически генерировать наборы синтетических данных на основе цифрового двойника города.
Участники рынка генерации синтетических данных:
- Корпорация Microsoft
- Обзор компании
- Бизнес-стратегия
- Основные предложения продуктов
- Финансовые показатели
- Ключевые показатели эффективности
- Анализ рисков
- Недавнее развитие
- Региональное присутствие
- SWOT-анализ
- Google LLC
- Корпорация NVIDIA
- GenRocket, Inc.
- Синтез ИИ
- Датаген
- Хейзи Лимитед.
- Gretel Labs, Inc.
- K2view Ltd.
- Amazon.com, Inc.
Последние события
- В марте 2024 года Hazy и Unbanx объявили о совместной работе над платформой управления данными Open Banking. Это совместный проект обеих компаний по внедрению этических кооперативов по обработке синтетических данных для обработки данных о финансовых транзакциях, ориентированных на хедж-фонды, аналитиков и другие финансовые учреждения.
- В июне 2024 года NVIDIA Nemotron-4 340B, оптимизированный для NVIDIA TensorRT-LLM и NVIDIA NeMo для здравоохранения, производства, розничной торговли и финансов, а также для разработки коммерческих приложений.
- В сентябре 2024 года Amazon запустила Amazon Bedrock, инструмент для генерации кода Python для создания синтетических данных. Инструмент Amazon Bedrock помогает клиентам создавать и масштабировать приложения генеративного ИИ. Это полностью управляемый сервис для разработки приложений генеративного ИИ.
- В октябре 2024 года Gretel и Google Cloud объединили усилия, чтобы упростить создание синтетических данных для аналитиков в BigQuery. Интеграция позволяет пользователям создавать синтетические версии своих наборов данных BigQuery с сохранением конфиденциальности. Партнерство позволяет клиентам защищать конфиденциальность данных, повышать доступность и ускорять тестирование и разработку.
- В октябре 2024 года компания Teledyne FLIR вывела на рынок Prism AIMMGen — не требующую соблюдения требований ITAR служба генерации синтетических данных на основе ИИ-моделей, предназначенная для системных интеграторов для создания продуктов ИИ/МО для служб быстрого реагирования, коммерческих и оборонных приложений.
- В октябре 2024 года компании Betterdata, MOSTLY AI, DataCebo и Rockfish Data получили контракты от Управления науки и технологий Министерства внутренней безопасности США (DHS) на разработку возможностей синтетических данных, позволяющих генерировать реальные шаблоны данных и одновременно снижать угрозы безопасности. Эти платформы генеративных данных, обеспечивающие конфиденциальность, призваны ускорить внедрение возможностей ИИ в приложениях корпоративного уровня.
- Report ID: 5711
- Published Date: Sep 16, 2025
- Report Format: PDF, PPT
- Ознакомьтесь с предварительным обзором ключевых рыночных тенденций и инсайтов
- Ознакомьтесь с примерами таблиц данных и разбивками по сегментам
- Оцените качество наших визуальных представлений данных
- Оцените структуру нашего отчёта и методологию исследования
- Получите представление об анализе конкурентной среды
- Поймите, как представлены региональные прогнозы
- Оцените глубину профилирования компаний и бенчмаркинга
- Предварительный просмотр того, как практические инсайты могут поддержать вашу стратегию
Изучите реальные данные и анализ
Часто задаваемые вопросы (FAQ)
Генерация синтетических данных Объем рыночного отчета
Бесплатный образец включает текущий и исторический объем рынка, тенденции роста, региональные графики и таблицы, профили компаний, прогнозы по сегментам и многое другое.
Связаться с нашим экспертом




Авторские права © 2026 Research Nester. Все права защищены.
